1.1 基本概念介绍
kafka特性
- 消息系统: Kafka和传统的消息中间件都具备流量削峰,缓冲,异步通信,扩展性等.另外,Kafka还提供了大多数消息中间件难以实现的消息顺序保障及回溯消费的功能
- 存储系统: 消息持久化到存盘,可以实现永久存储
- 流式处理平台: Kafka提供了流式处理类库
Kafka架构
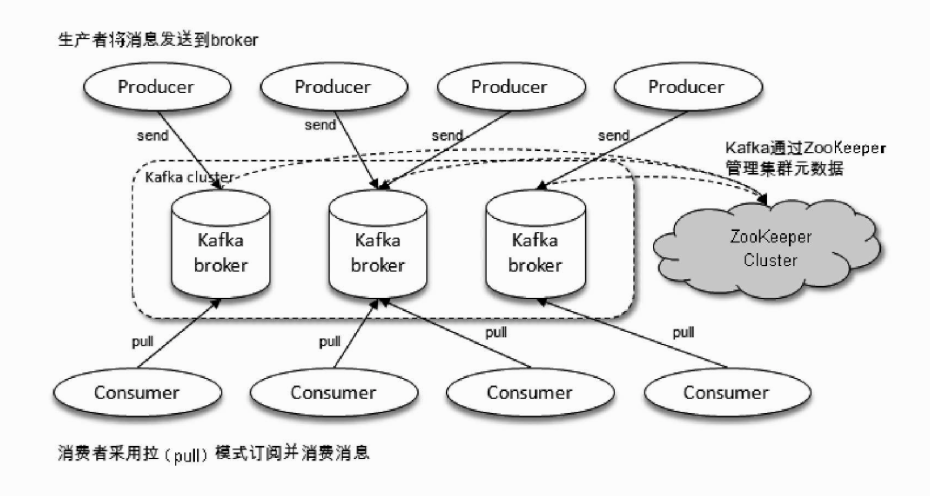
一个Kafka体系主要包括:
- producer: 生产者
- broker: kafka节点服务器
- consumer: 消费者
- zookeeper: 负责管理kafka集群元数据,集群选举等
producer将消息发送到Broker,Broker负责将受到的消息存储到磁盘中,Consumer负责从Broker订阅并消费消息.
基础概念
- Kafka 通过 topic 对存储的流数据进行分类。
- 每条记录中包含一个key,一个value和一个timestamp(时间戳).
- kafka保留所有的发布记录(无论是否已经被消费过).通过一个可配置的参数—保留期限来控制记录存在时间.
举个例子, 如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被抛弃并释放磁盘空间。
kafka核心API
- Producer API : 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
- Consumer API: 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
- Streams API: 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
- Connector API: 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
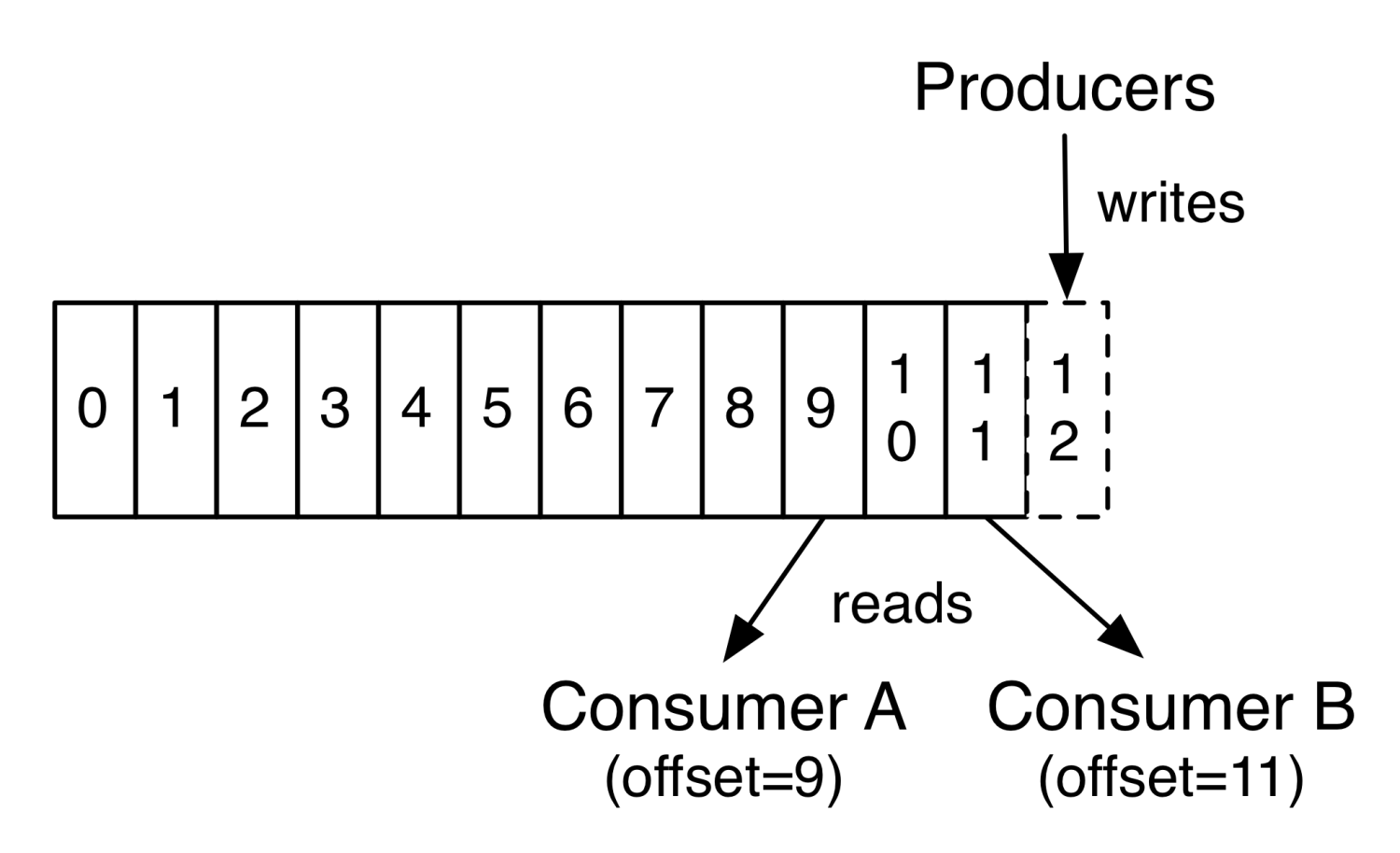
理解topics和Partition和offset
Topic: 就是数据主题,生产者将消息发送到特点的主题.消费者负责订阅主题并进行消费.
Partition: 一个Topic可以划分成多个partition(分区).但是一个分区只属于单个主题.很多时候也会将partition称为主题分区(Topic-Partition).同一个主题下的不同分区包含的消息也不同.分区在存储层面可以看做一个追加的日志(Log)文件.
一个主题的分区可以在不同的节点服务器上,所有的消息会均匀的分配到不同的分区中(也就是不同的节点服务器),这样可以提高磁盘IO和性能.在创建主题的时候可以设置分区数量,当然也可以在主题创建完成后去修改分区数量.通过增加分区的数量实现水平扩展.
好比是为公路运输,不同的起始点和目的地需要修不同高速公路(主题),高速公路上可以提供多条车道(分区),流量大的公路多修几条车道保证畅通,流量小的公路少修几条车道避免浪费。收费站好比消费者,车多的时候多开几个一起收费避免堵在路上,车少的时候开几个让汽车并道就好了
Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。对于每一个topic, Kafka集群都会维持一个分区日志,如下所示:
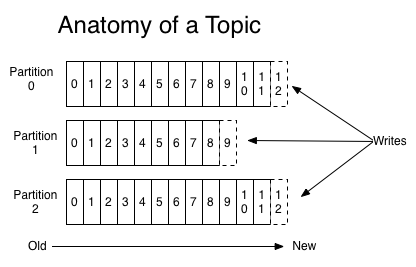
每个partition分区都是有序切不可变的记录集.并且不断的追加到结构化的commit log文件.
Offset: 消息被存储到分区的日志文件时会分片一个偏移量(offset).offset是消息在分区中的唯一表示.kafka通过它来保障消息在分区内的顺序.
不过Offset并不跨越分区,也就是说Kafka保证的是分区有序,而不是主题有序.
在每一个消费者中唯一保存的元数据是offset(偏移量)即消费在log中的位置.偏移量由消费者所控制:通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从”现在”开始消费。